Showing 119 of 119on this page. Filters & sort apply to loaded results; URL updates for sharing.119 of 119 on this page
How predictable is language model benchmark performance? | Epoch AI
A Benchmark Model for Language Models Towards Increased Transparency
Language model benchmark - Wikipedia
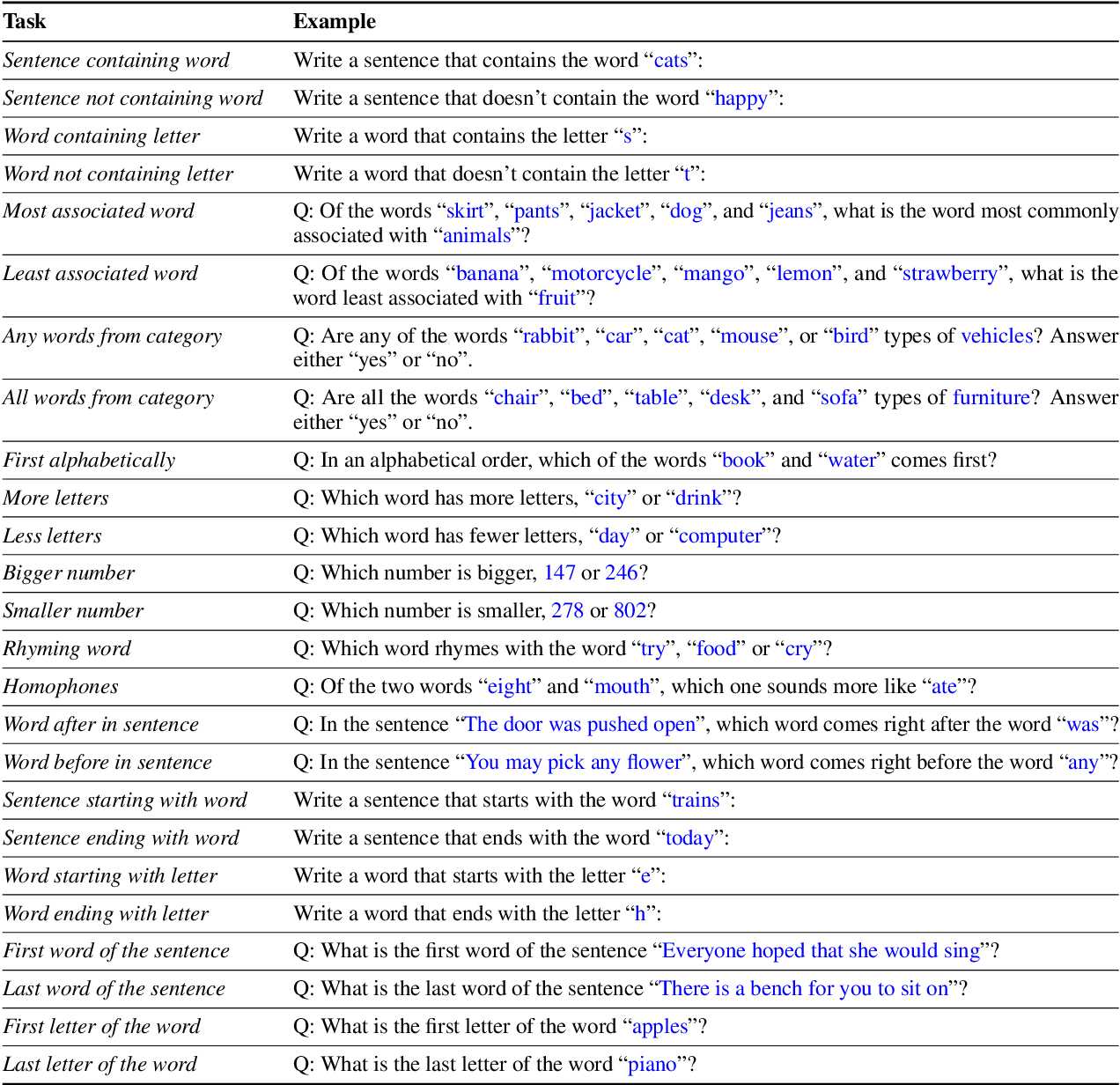
Table 2 from LMentry: A Language Model Benchmark of Elementary Language ...
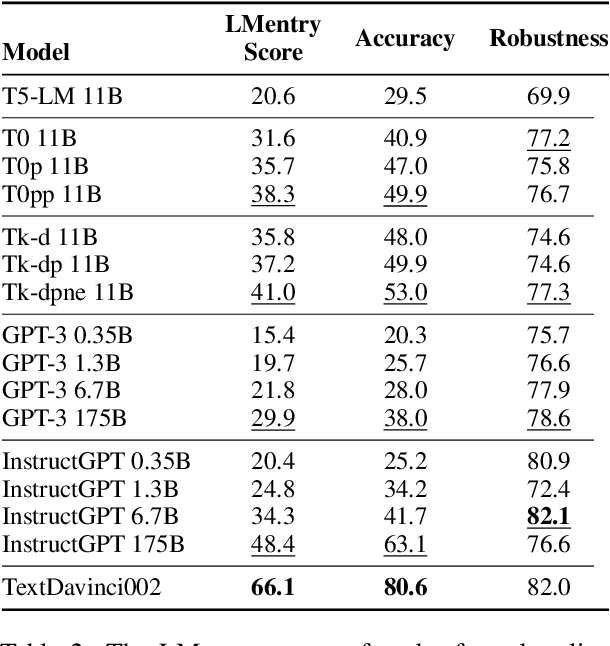
LMentry: A Language Model Benchmark of Elementary Language Tasks - ACL ...
LMentry: A Language Model Benchmark of Elementary Language Tasks | DeepAI
(PDF) CS-Eval: A Comprehensive Large Language Model Benchmark for ...
LLMFAO Large Language Model Benchmark | Kaggle
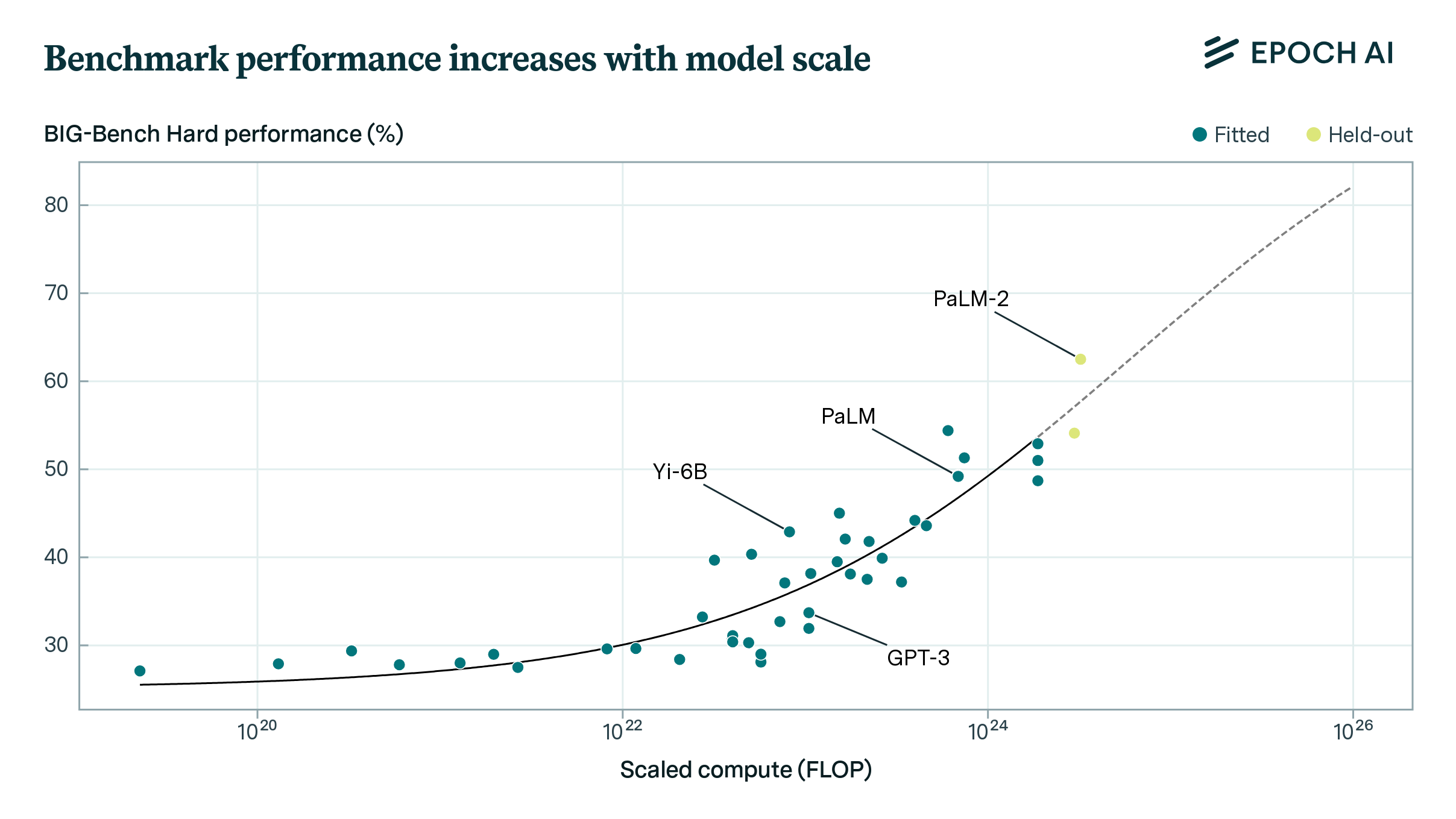
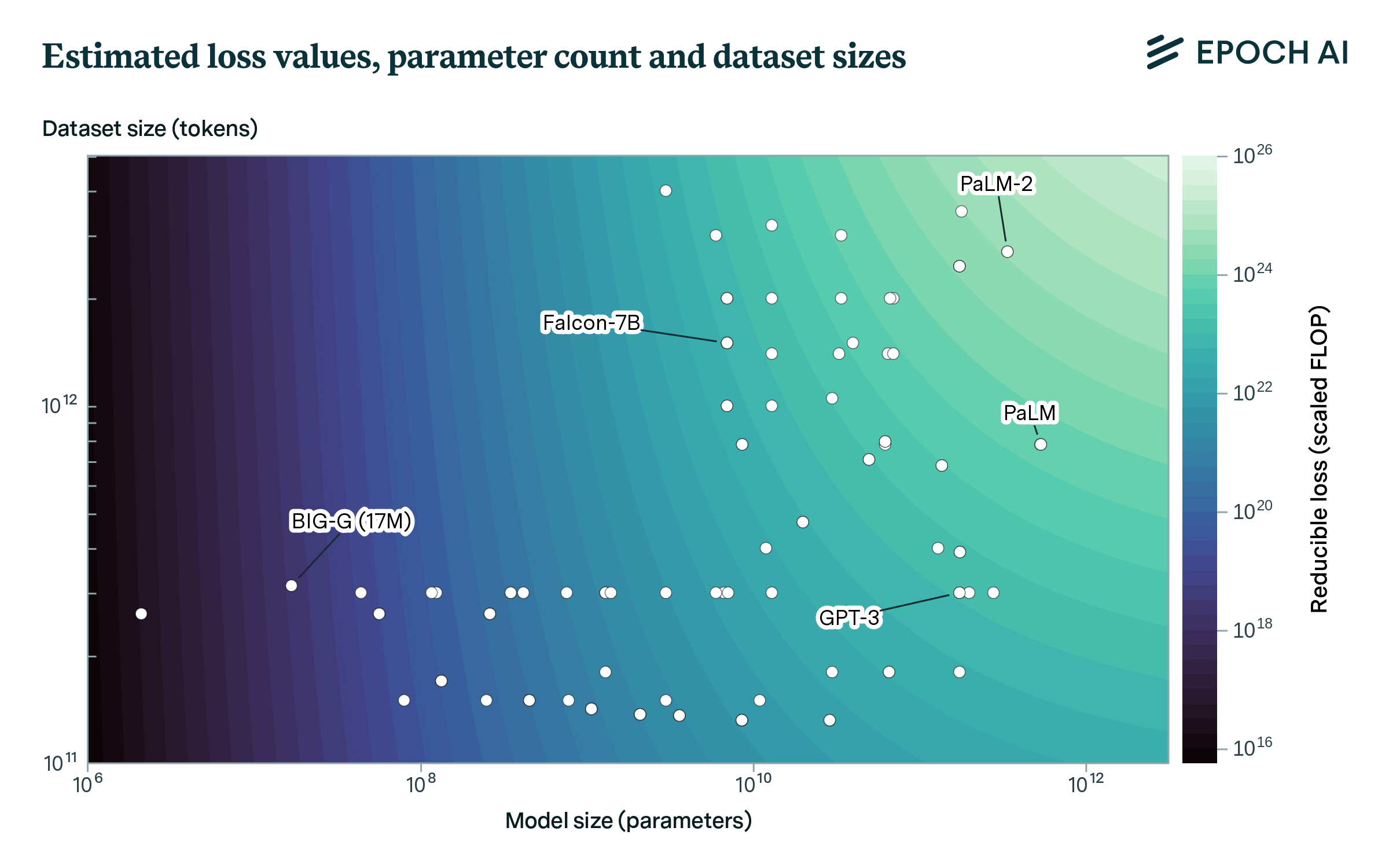
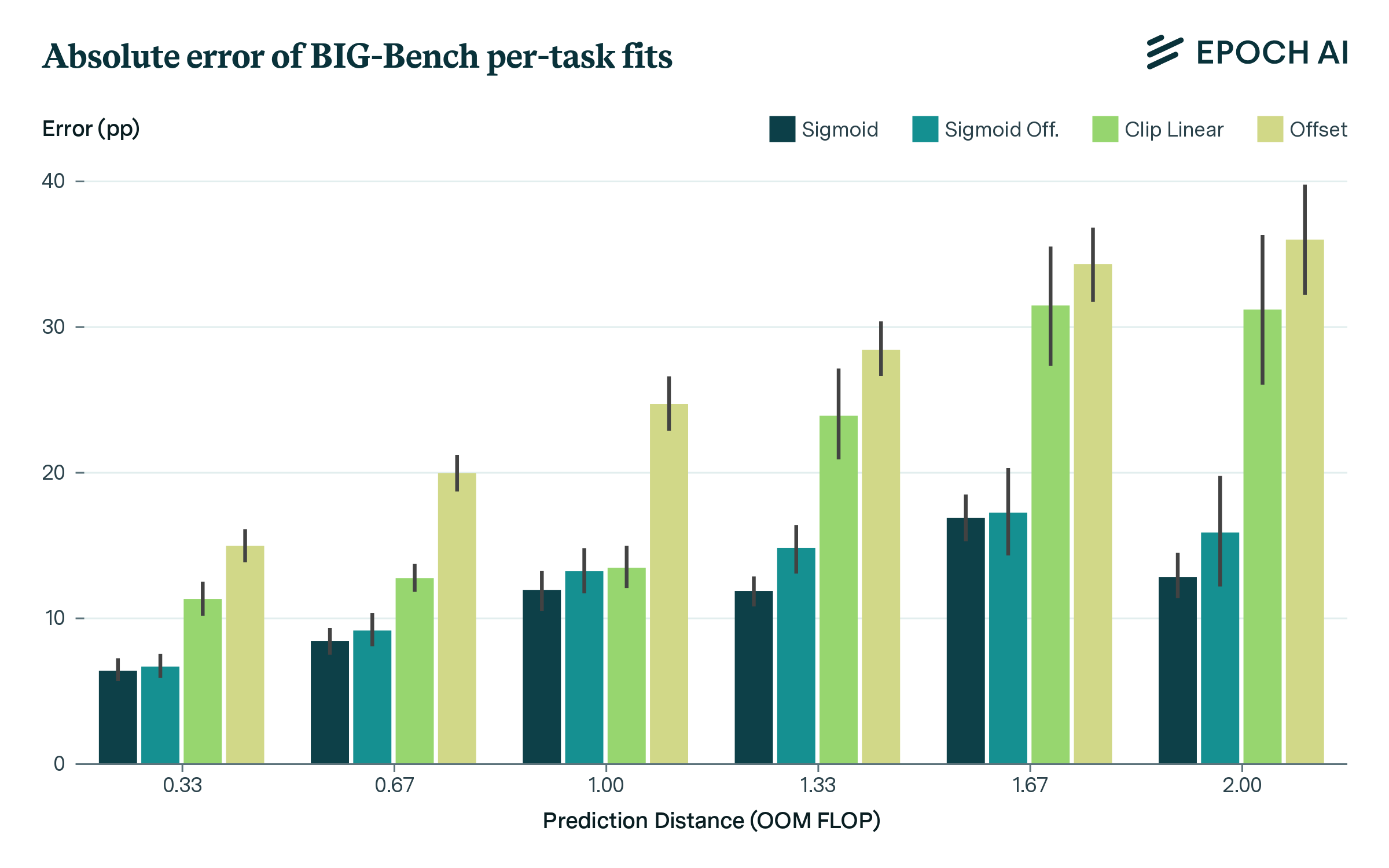
How Predictable Is Language Model Benchmark Performance? | Epoch AI
Table 1 from LMentry: A Language Model Benchmark of Elementary Language ...
MME: Multimodal Language Model Benchmark | PDF | Cognitive Science ...
DataComp for Language Models (DCLM): An AI Benchmark for Language Model ...
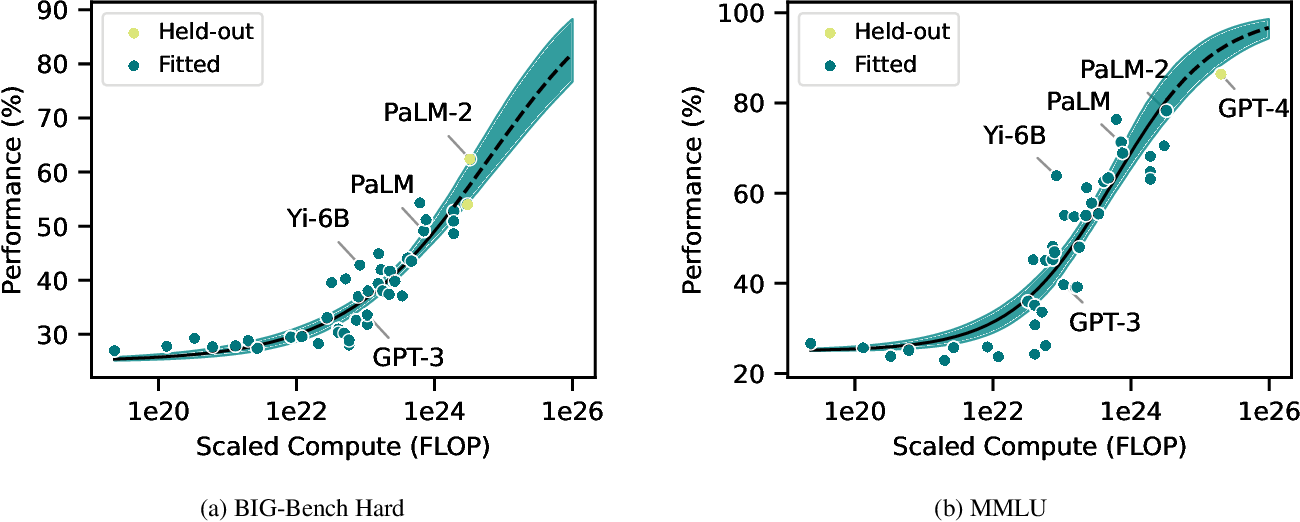
Figure 1 from How predictable is language model benchmark performance ...
A Survey on Large Language Model Benchmarks | alphaXiv
A Survey on Large Language Model Benchmarks - AI for Dummies ...
Language Model Benchmarks | mlcommons/training | DeepWiki
Benchmark comparison of Large Language Models | PDF
What are Large Language Model (LLM) Benchmarks? | Shunichi AKAZAWA
Developing a Scalable Benchmark for Assessing Large Language Models in ...
Paper page - Do Large Language Model Benchmarks Test Reliability?
(PDF) Language Model Evolutionary Algorithms for Recommender Systems ...
Understanding Large Language Model (LLM) Benchmarks | by Vivedha Elango ...
(PDF) Enterprise Benchmarks for Large Language Model Evaluation
LLM Benchmark. Large Language Model Benchmark, is a… | by Vinit Shah ...
CS-Bench:A Comprehensive Benchmark for Large Language Models towards ...
Choosing the right language model for your NLP use case | by Dr. Janna ...
LLM Benchmarks: Understanding Language Model Performance
(PDF) A Benchmark Evaluation of Multilingual Large Language Models for ...
StatEval: A Comprehensive Benchmark for Large Language Models in ...
Survey of Different Large Language Model Architectures | S-Logix
Measuring what Matters: Construct Validity in Large Language Model ...
Introducing A Benchmark Model Gemini By Google - AiThority
Benchmarking Benchmark Leakage in Large Language Models | AI Research ...
[논문 리뷰] Lost in Benchmarks? Rethinking Large Language Model ...
(PDF) Survey of Different Large Language Model Architectures: Trends ...
Large Language Model Evaluation in 2024: 5 Methods
A Survey on Large Language Model Benchmarks を手がかりに学ぶ:LLMベンチマークの全体像と実務で ...
GLBench: A Comprehensive Benchmark for Graph with Large Language Models ...
[논문 리뷰] The Vulnerability of Language Model Benchmarks: Do They ...
5 Best Large Language Models (LLMs) in December 2024 - Unite.AI
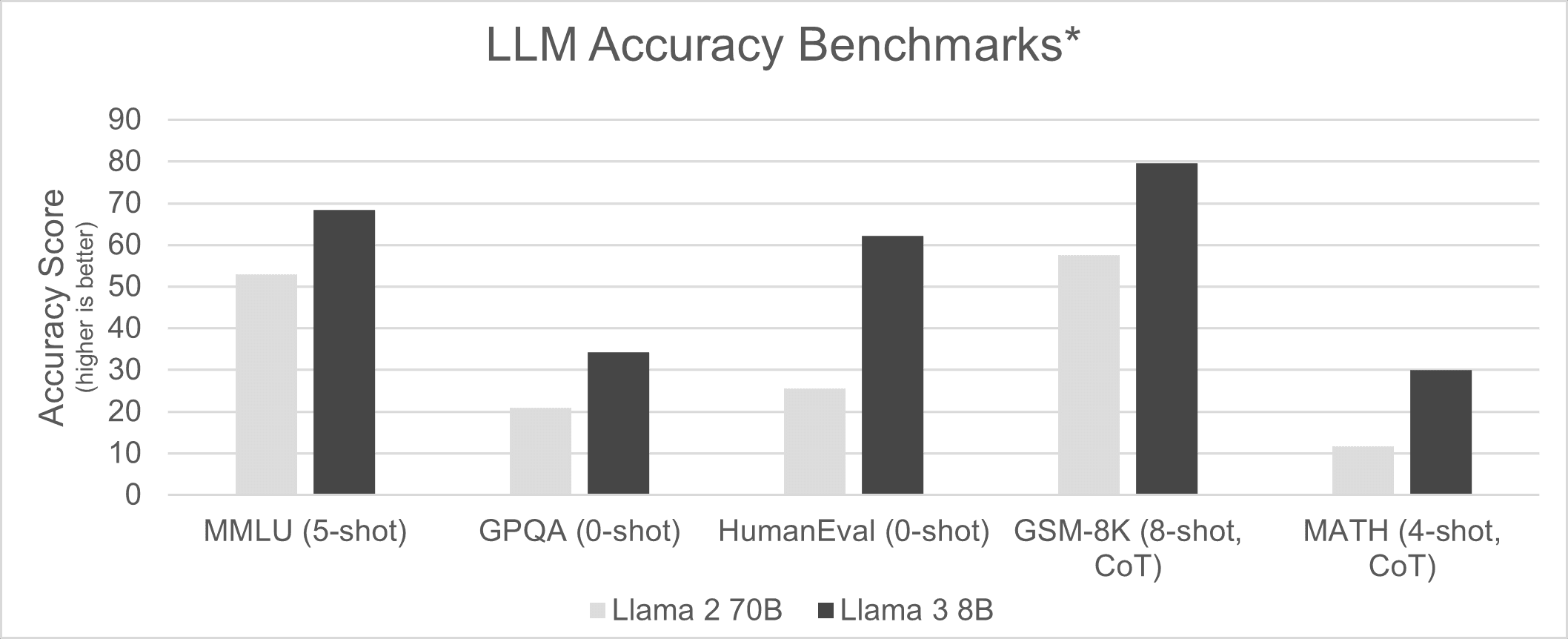
How Does Llama-2 Compare to GPT-4/3.5 and Other AI Language Models
Updated January 2025: a Comparative Analysis of Leading Large Language ...
The Best Open Large Language Models | NextBigFuture.com
Meet AgentBench: A Multidimensional Benchmark Which Has Been Developed ...
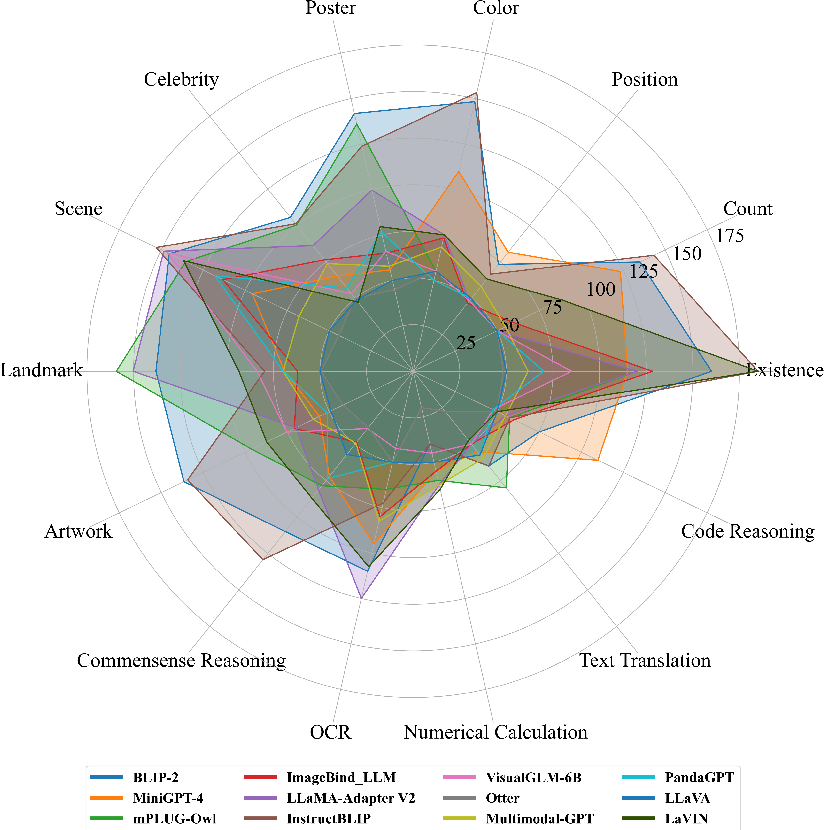
Figure 3 from MME: A Comprehensive Evaluation Benchmark for Multimodal ...
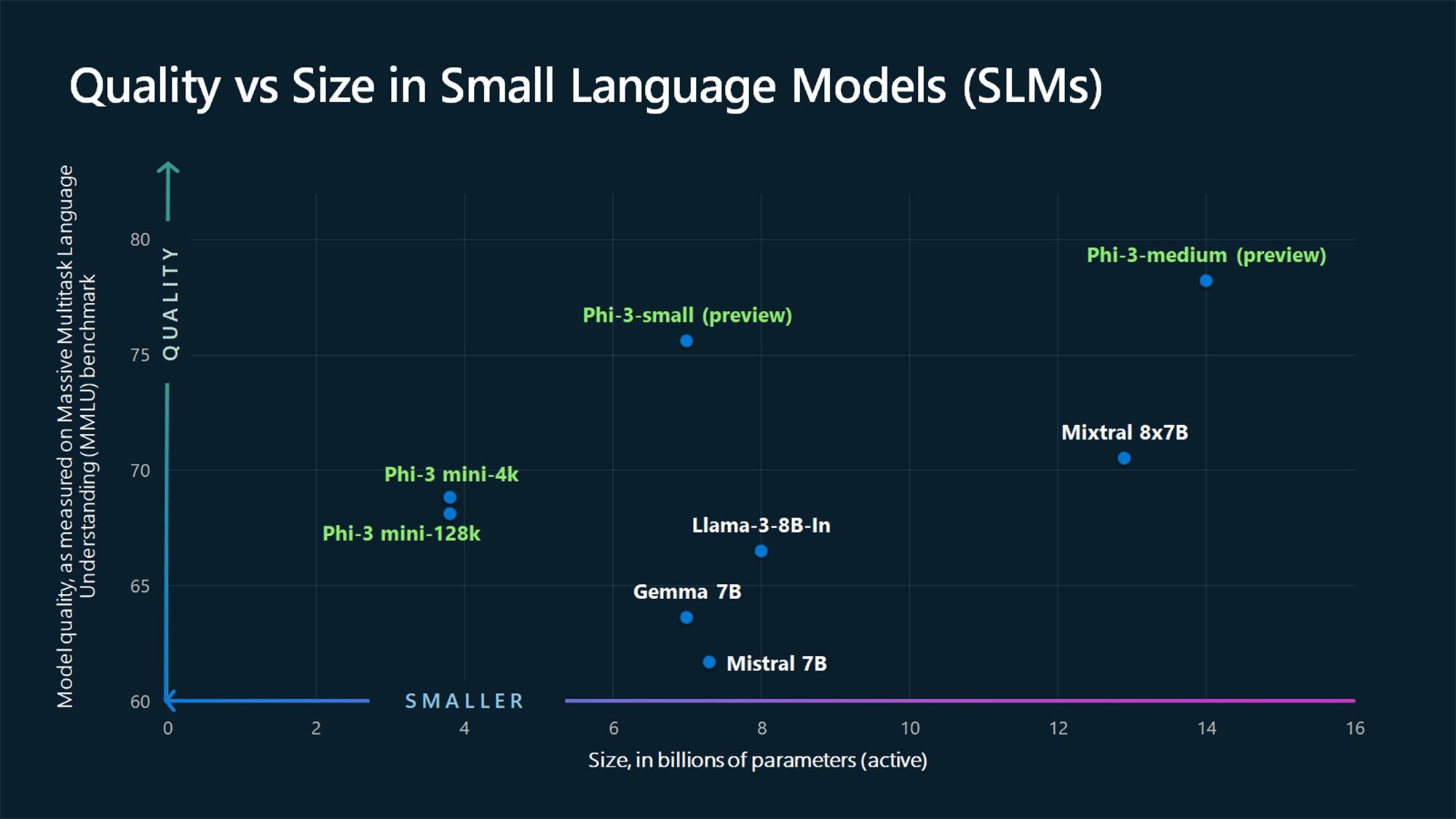
Beyond LLMs: Here's Why Small Language Models Are the Future of AI
Evaluating Large Language Models
Performance Metrics and Risk Evaluation in Large Language Models (LLM ...
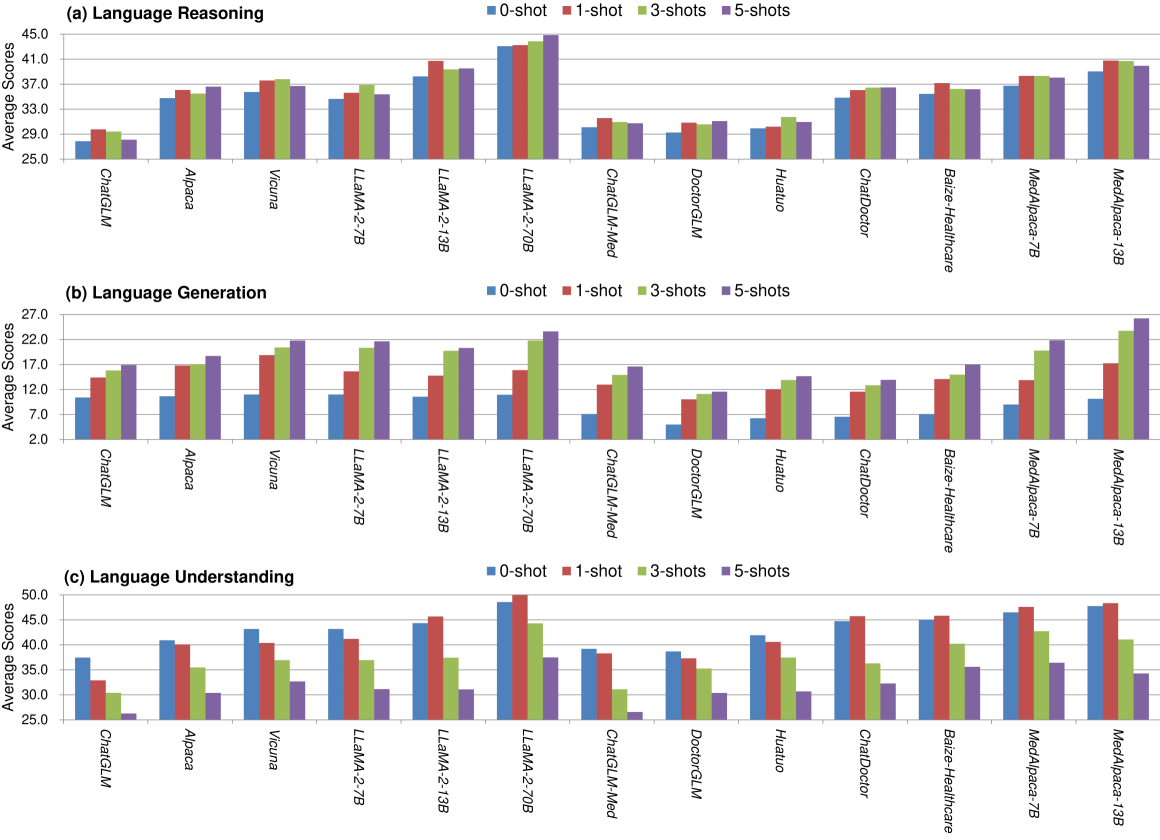
Unlocking the Potential of Large Language Models for Clinical Text ...
Existing benchmarks either measure properties of open-ended language ...
A High-level Overview of Large Language Models - RBC Borealis
Evaluating Large Language Models Benchmarks & Challenges
(PDF) Is Your Benchmark (Still) Useful? Dynamic Benchmarking for Code ...
Paper page - Assessing Small Language Models for Code Generation: An ...
(PDF) Comparative evaluation and performance of large language models ...
Benchmarking Large Language Models on Network Optimization | PDF
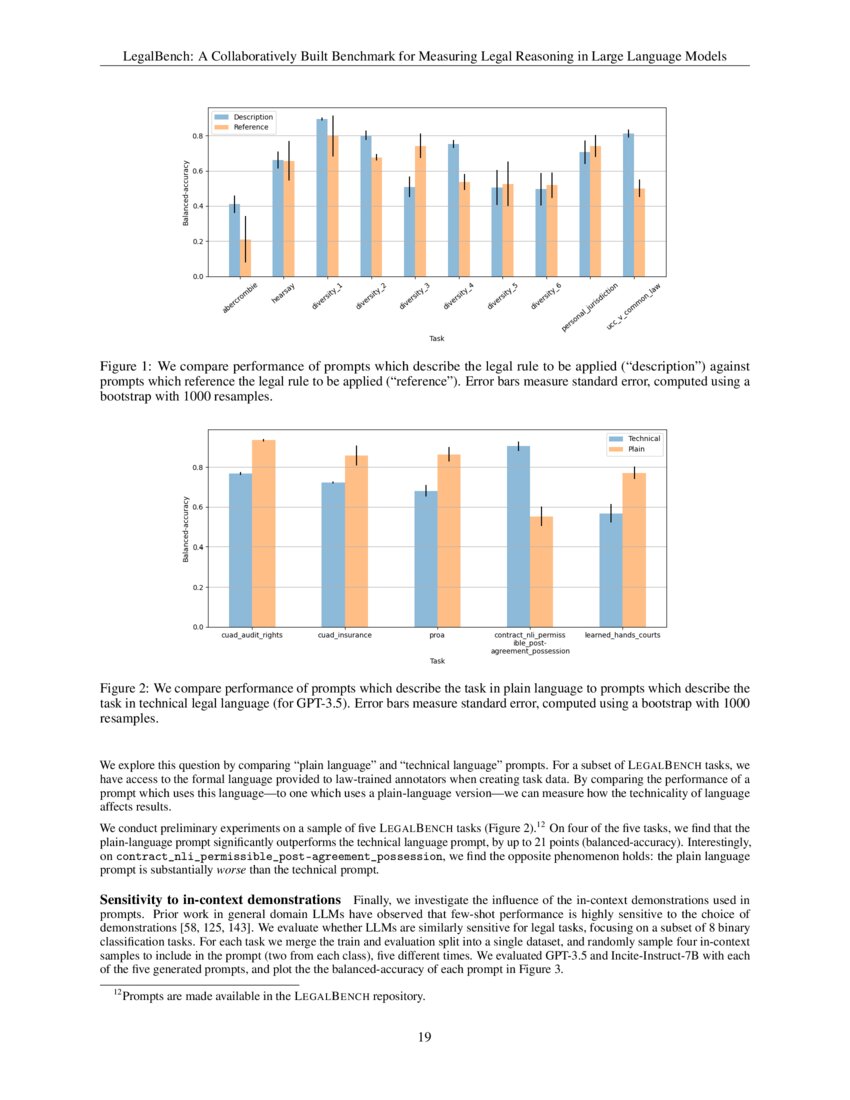
LegalBench: A Collaboratively Built Benchmark for Measuring Legal ...
Benchmarking Language Models in NLP | The Rasa Blog
Benchmarking Language Models using the Together Research Computer ...
LongICLBench Benchmark: Evaluating Large Language Models on Long In ...
Benchmarking Knowledge and Capability of Large Language Models in ...
Overcoming the Limitations of Large Language Models | by Dr. Janna ...
Small language models are better then LLM's? Microsoft Research has ...
LLM(언어모델) Benchmark 항목, 용어 정리
PhonologyBench: Evaluating Phonological Skills of Large Language Models ...
Leveraging Open Large Language Models for Multilingual Policy Topic ...
(PDF) Benchmark Evaluations, Applications, and Challenges of Large ...
Exploring and Comparing Open-Source Large Language Models
Figure 2 from A Comprehensive Evaluation of Large Language Models on ...
Mastering Benchmarks: The Path to Prodigy Language Models | by S Shakir ...
Benchmarking Large Language Models with a Unified Performance Ranking ...
Benchmarking Multi-Image Understanding in Vision and Language Models ...
All Languages Matter Benchmark (ALM-bench): A Comprehensive Evaluation ...
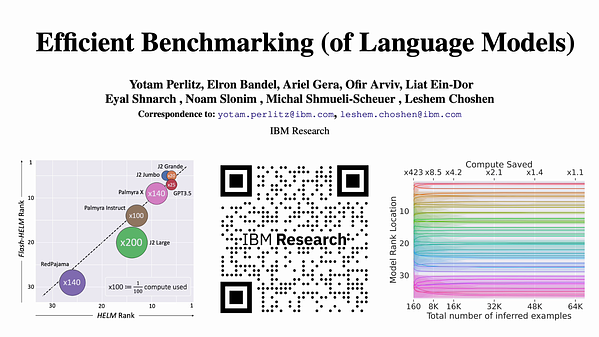
Figure 11 from Efficient Benchmarking (of Language Models) | Semantic ...
Benchmarking Large Language Models As AI Research Agents
[논문 리뷰] Benchmark Evaluations, Applications, and Challenges of Large ...
LLM Benchmarks: Guide to Evaluating Language Models | Deepgram
(PDF) Assessing and Advancing Benchmarks for Evaluating Large Language ...
35,000+ Large Language Models in Curated Directory with Benchmarks and ...
Evaluating Large Language Models on Clinical & Biomedical NLP ...
Are Large Language Models Memorizing Bug Benchmarks? | AI Research ...
New Benchmarks Test the Limits of Large Language Models
[论文评述] DesignProbe: A Graphic Design Benchmark for Multimodal Large ...
(PDF) Generating Benchmarks for Factuality Evaluation of Language Models
Benchmarking Large Language Models from Open and Closed Source Models ...
We benchmarked 12 small language models across 8 tasks to find the best ...
Small Language Models. An introduction to SLMs with prototype… | by ...
Efficient Benchmarking (of Language Models) | Underline
Explainable Pre-Trained Language Models for Sentiment Analysis in Low ...
Large Language Models - DDN
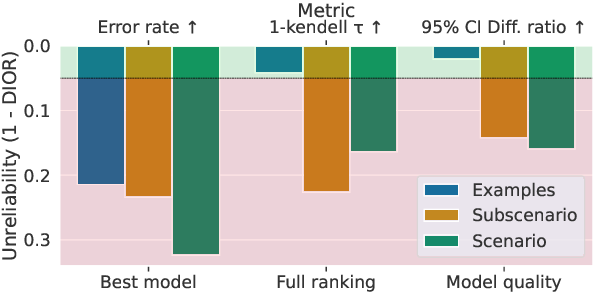
Figure 3 from Efficient Benchmarking (of Language Models) | Semantic ...
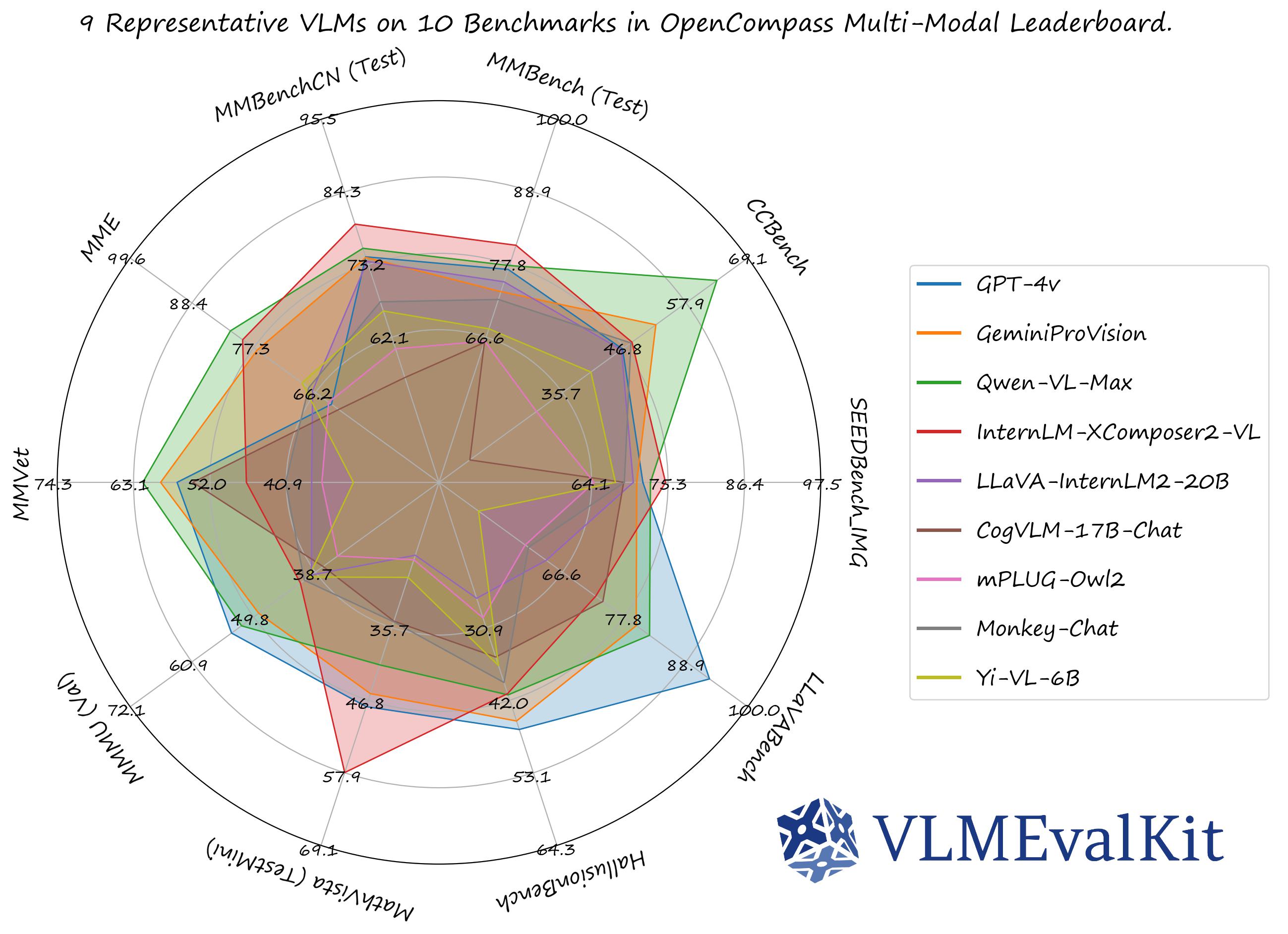
GitHub - mfarre/VLMEvalKit-official: Open-source evaluation toolkit of ...
What are LLM Benchmarks?
一文彻底搞懂大模型 - 基准测试(Benchmark)_自然语言处理_大模型与自然语言处理-DeepSeek技术社区
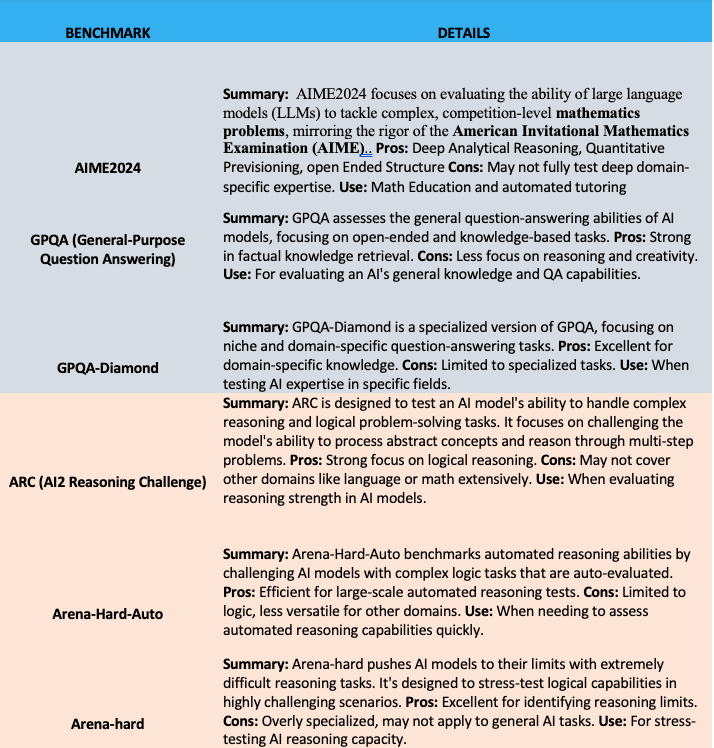
40 Top Research-Backed LLM Benchmarks and Where To Use Them
How Do We Evaluate LLMs Performance Effectively?
Decoding 21 LLM Benchmarks: What You Need to Know
Understanding LLM Benchmarks: Evaluating the Performance of Large ...
LLM Benchmarks in Life Sciences: Comprehensive Overview | IntuitionLabs
AK on Twitter: "Generating Benchmarks for Factuality Evaluation of ...
Paper page - Measuring what Matters: Construct Validity in Large ...
8. GPT Series — LLM Foundations
The Ultimate Guide to Bench-marking AI: Evaluating the Intelligence of ...
Exploring LLMs Speed Benchmarks: Independent Analysis
FedLLM-Bench: Realistic Benchmarks for Federated Learning of Large ...
Figure 3 from Risk Taxonomy, Mitigation, and Assessment Benchmarks of ...
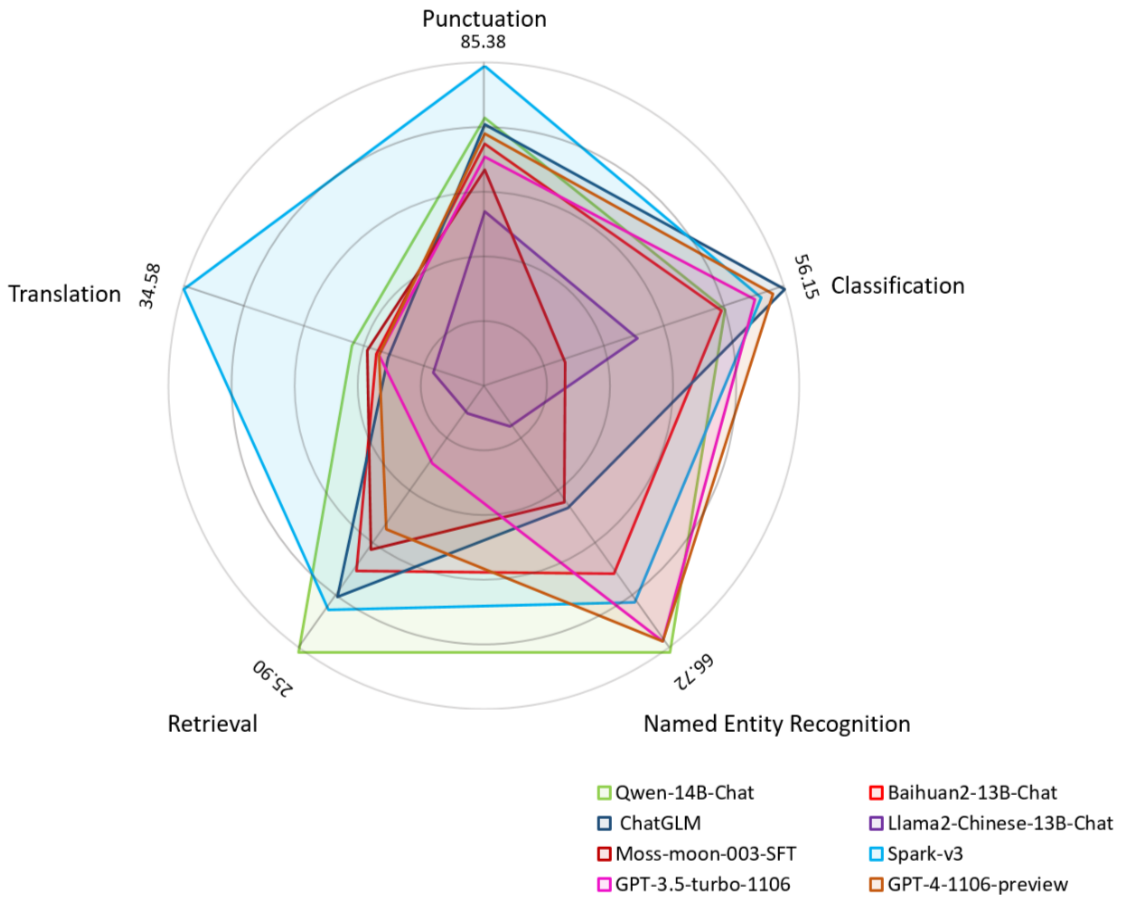
[논문 리뷰] C$^{3}$Bench: A Comprehensive Classical Chinese Understanding ...
Paper page - When Benchmarks are Targets: Revealing the Sensitivity of ...
LLM Evaluation: Key Metrics, Best Practices and Frameworks
LLMs: Bigger is Not Always Better | AI Platform Alliance
A Comprehensive Comparative Analysis of LLMs
LLM-Planning-Lecture

















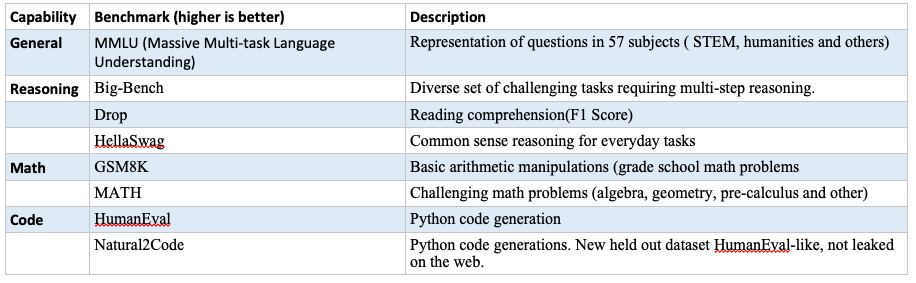

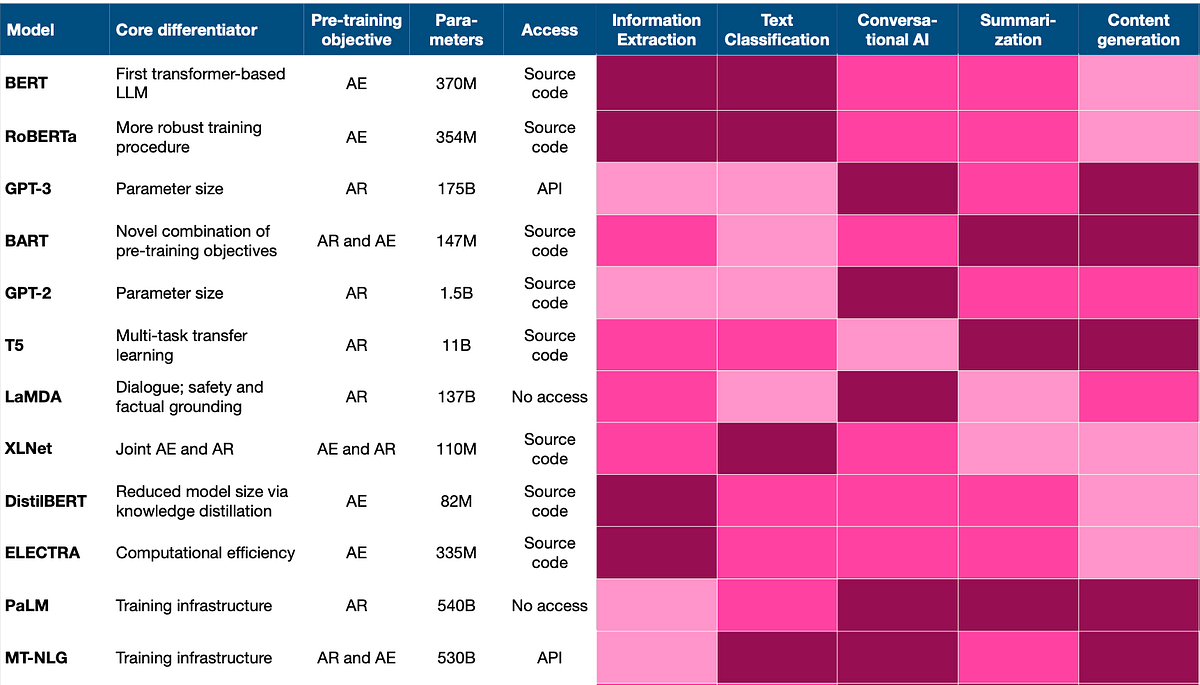
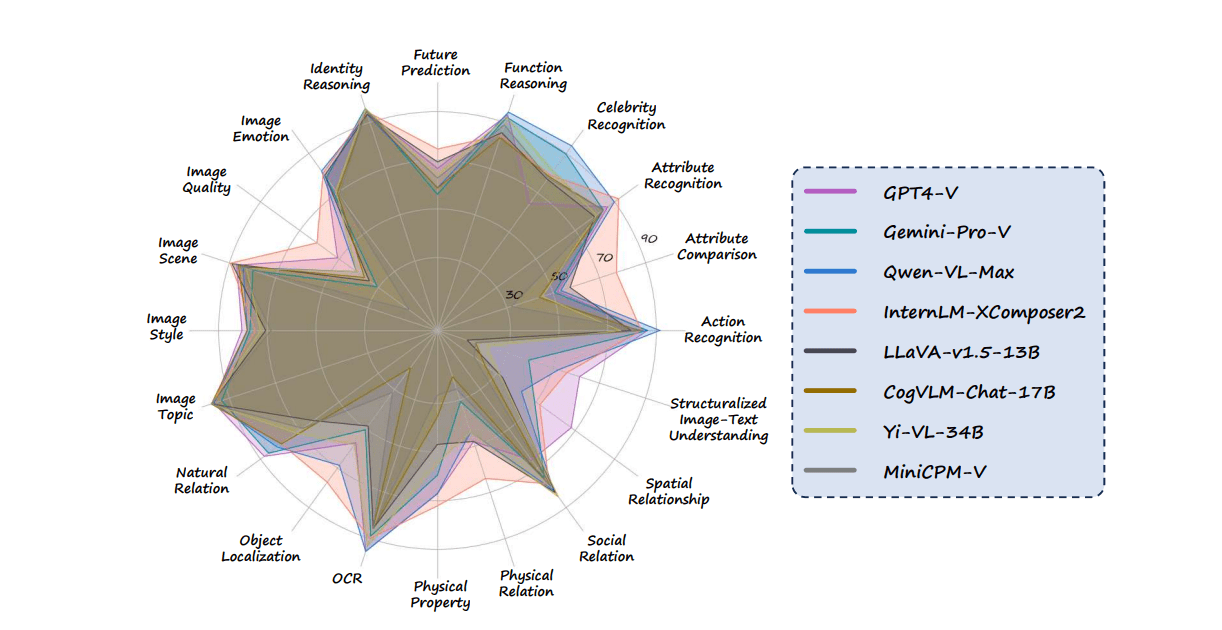




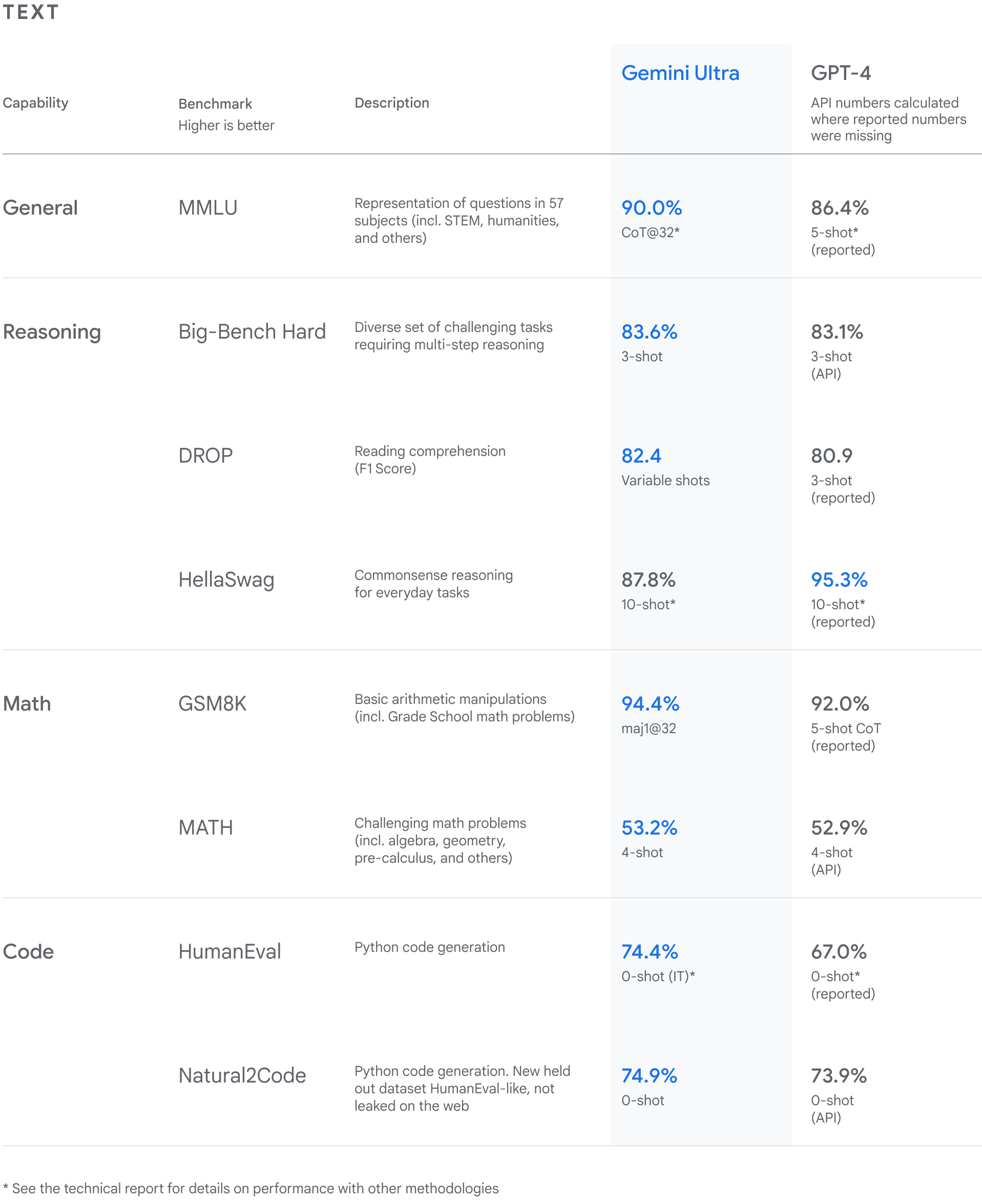
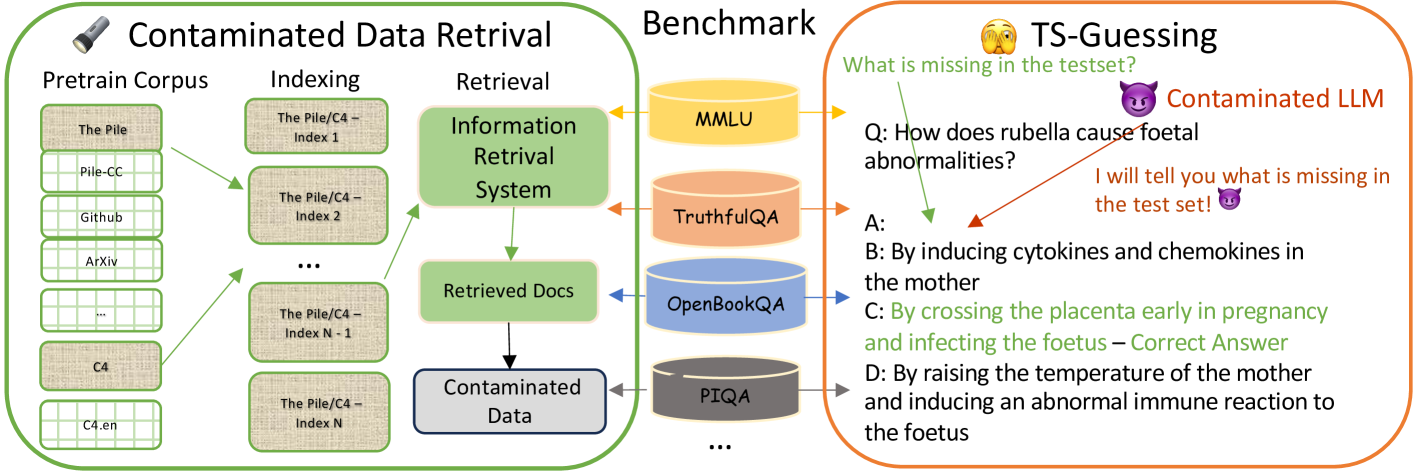






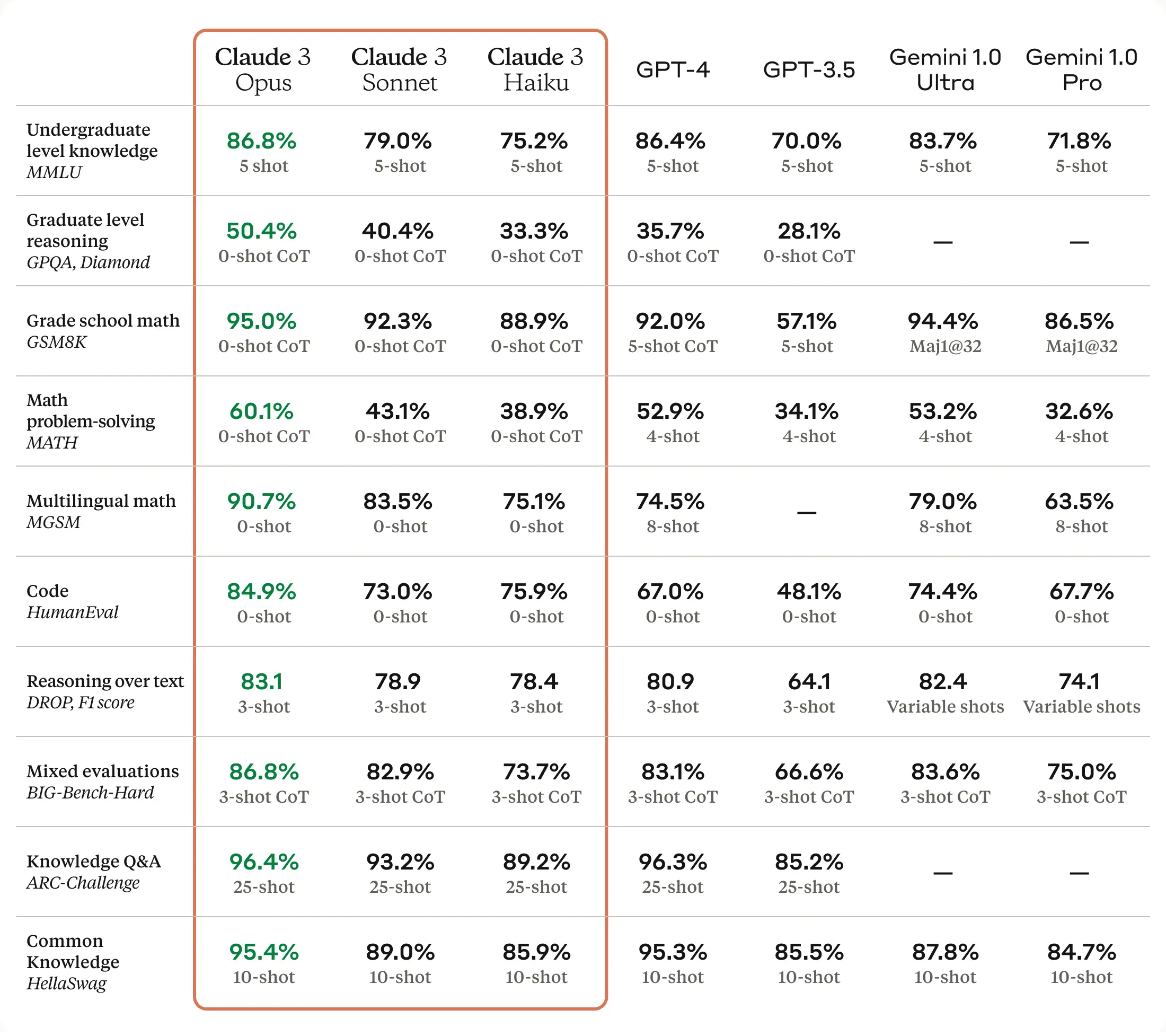
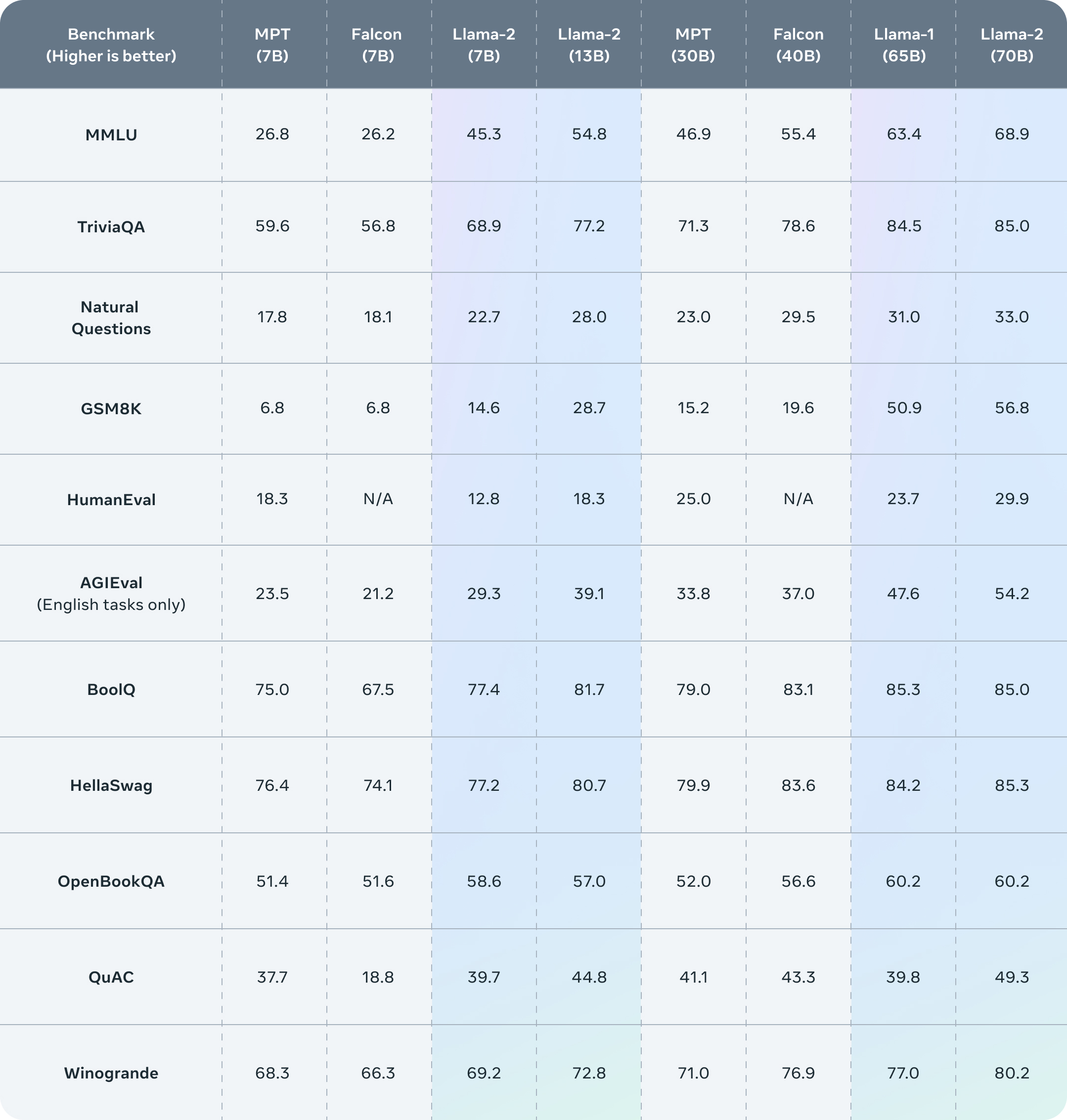
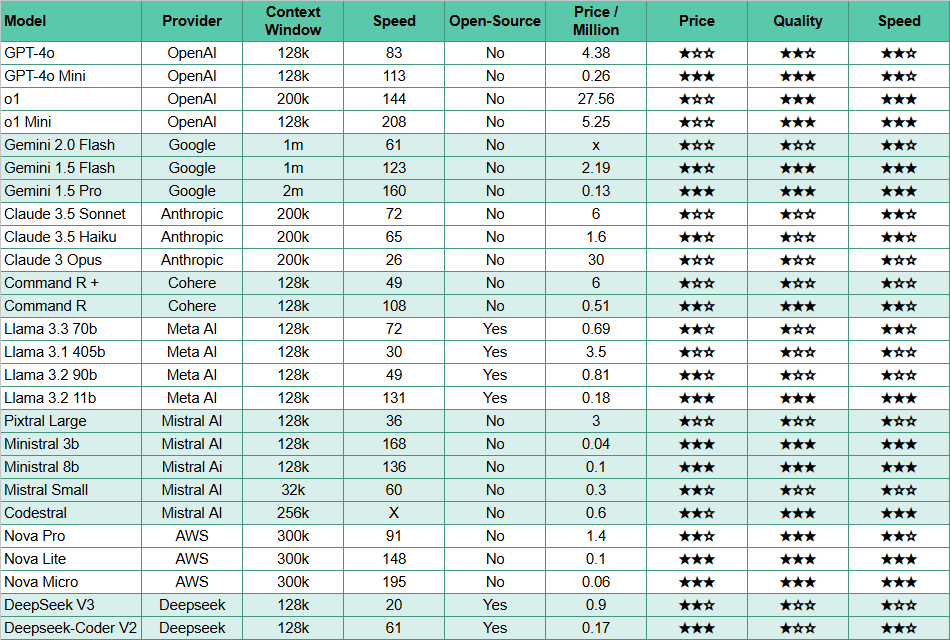











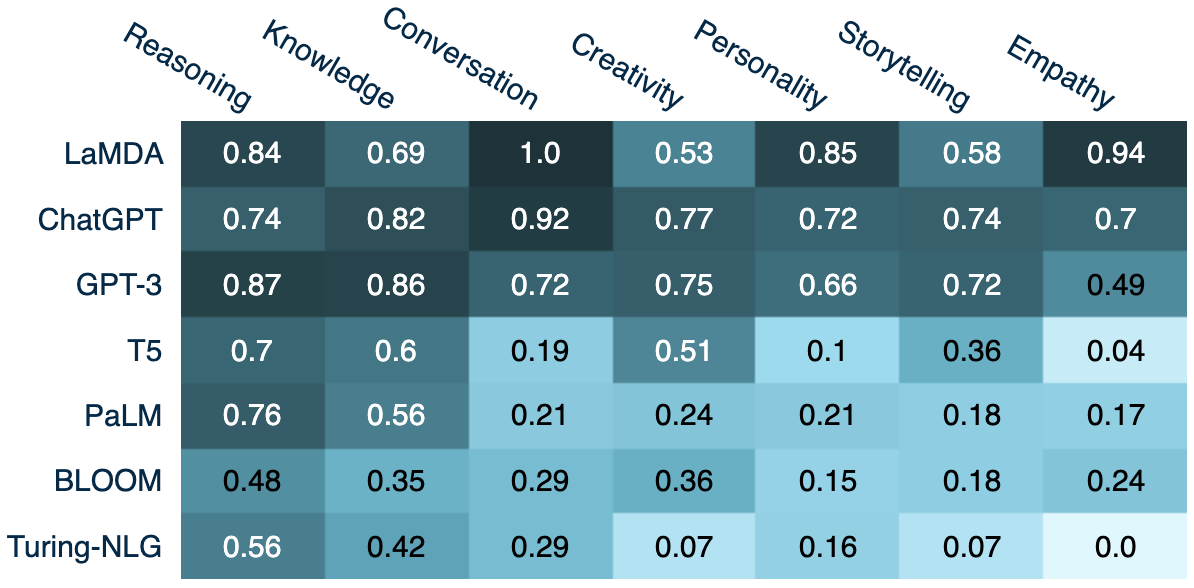

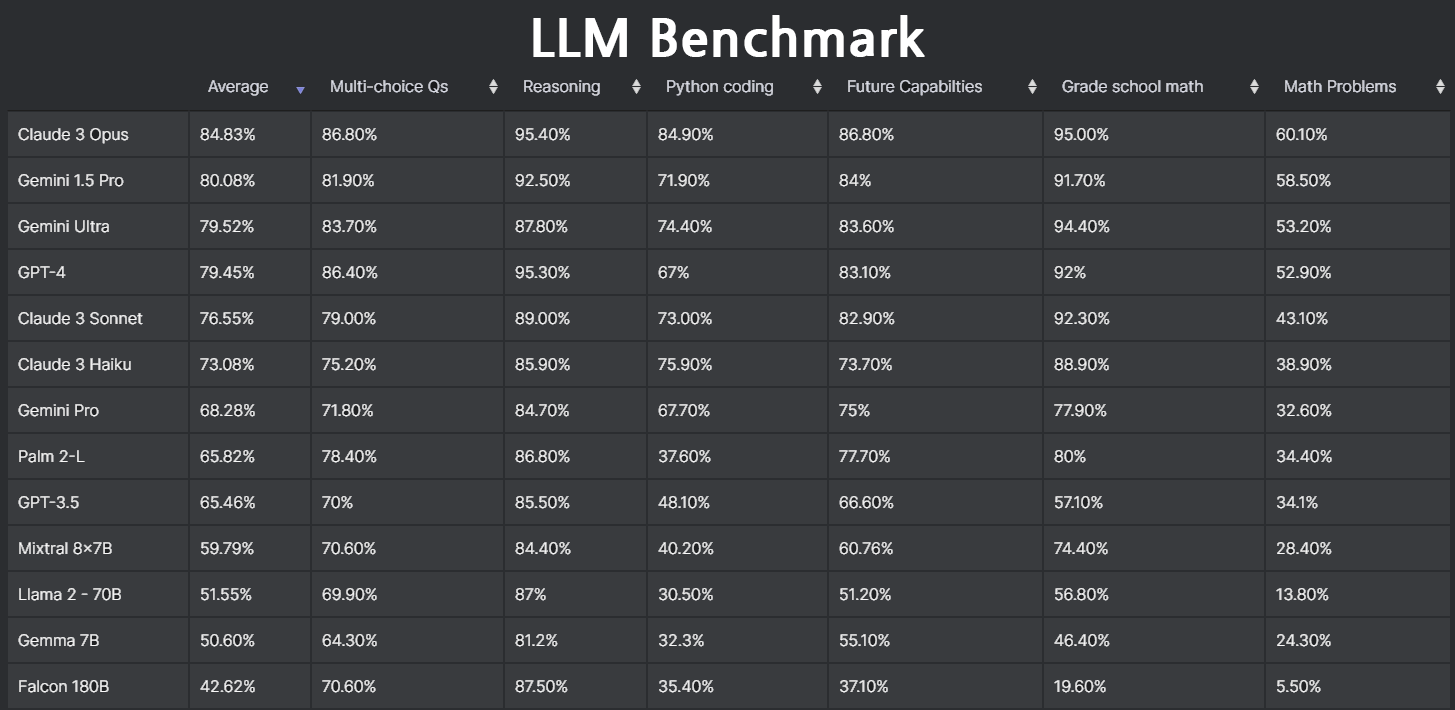



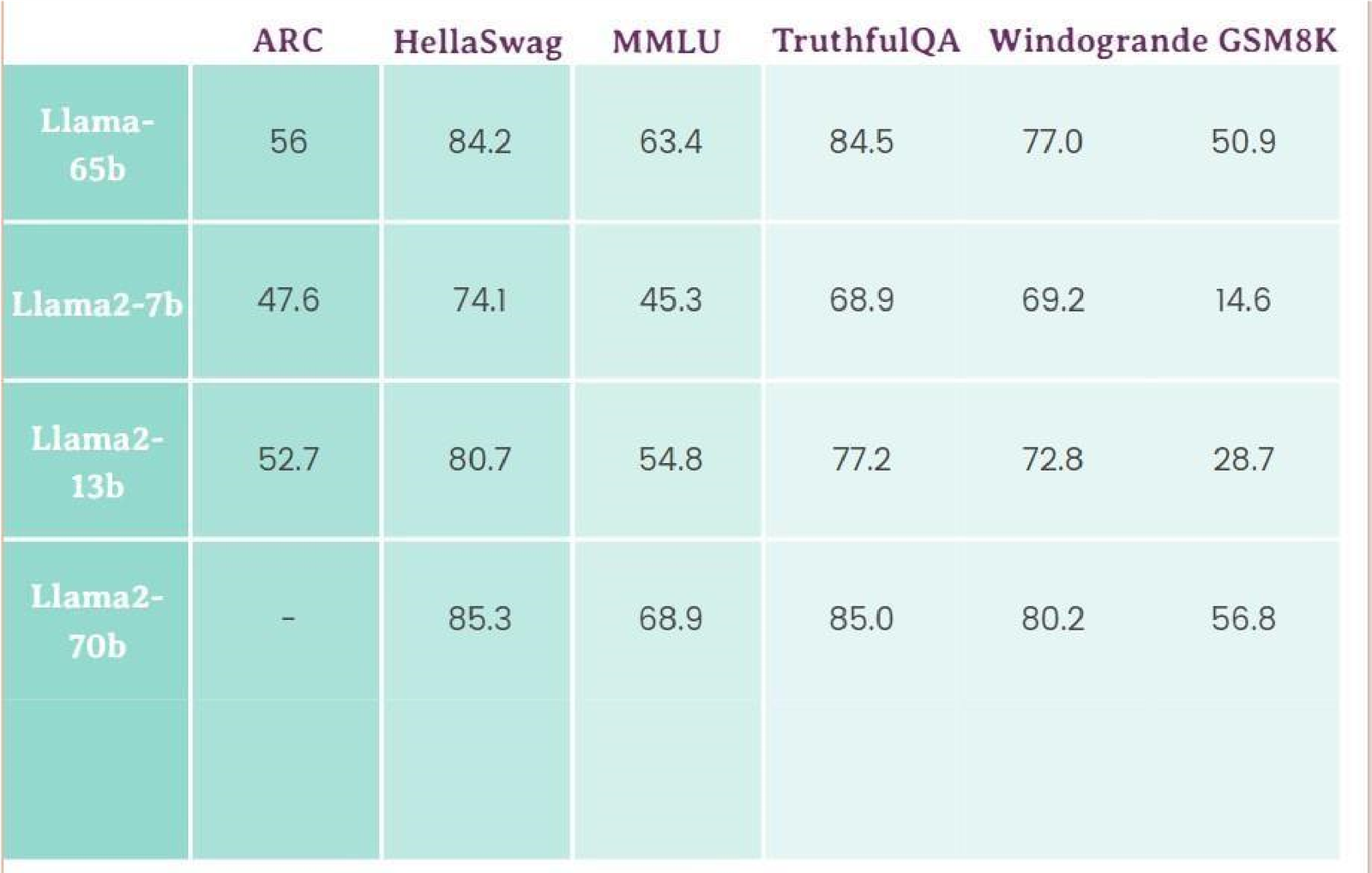

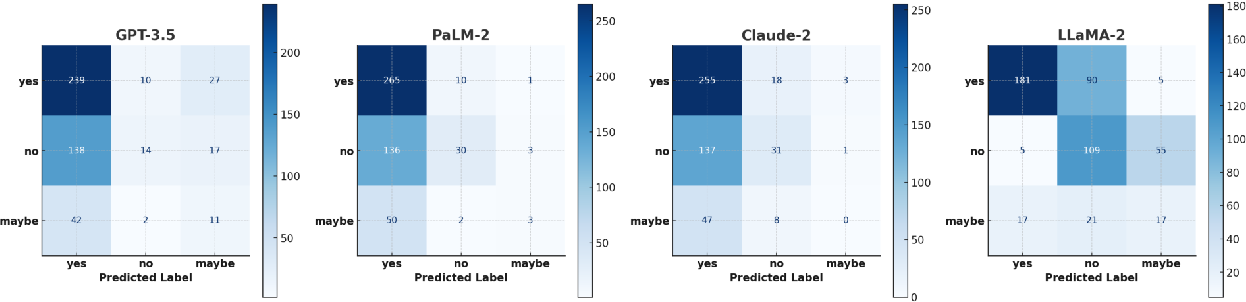

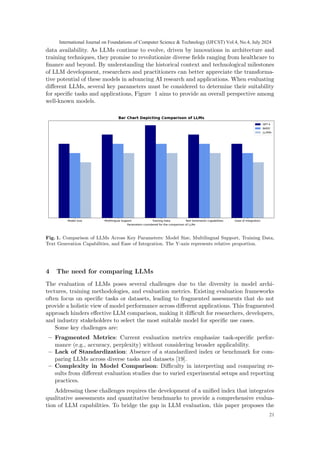
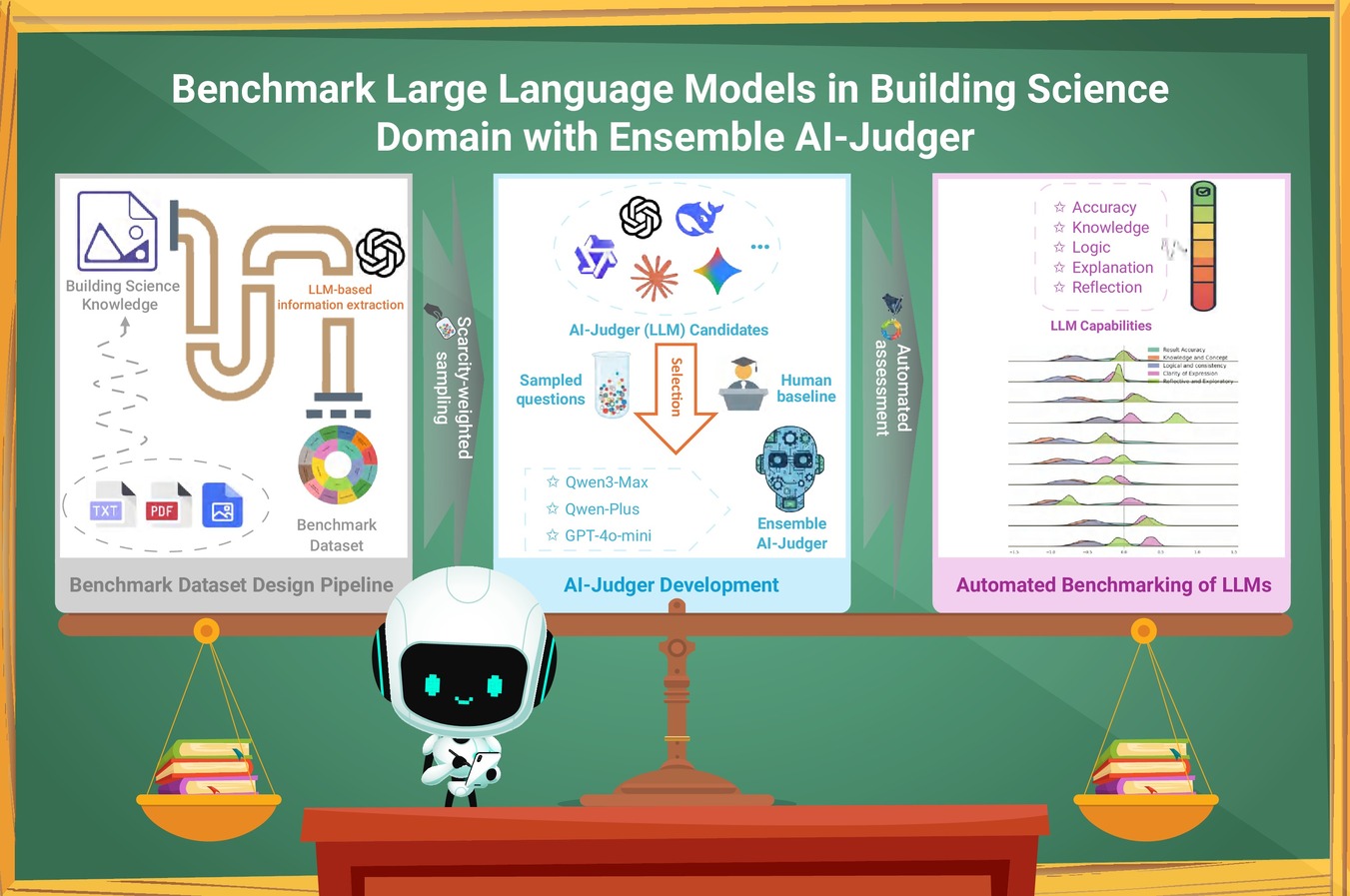



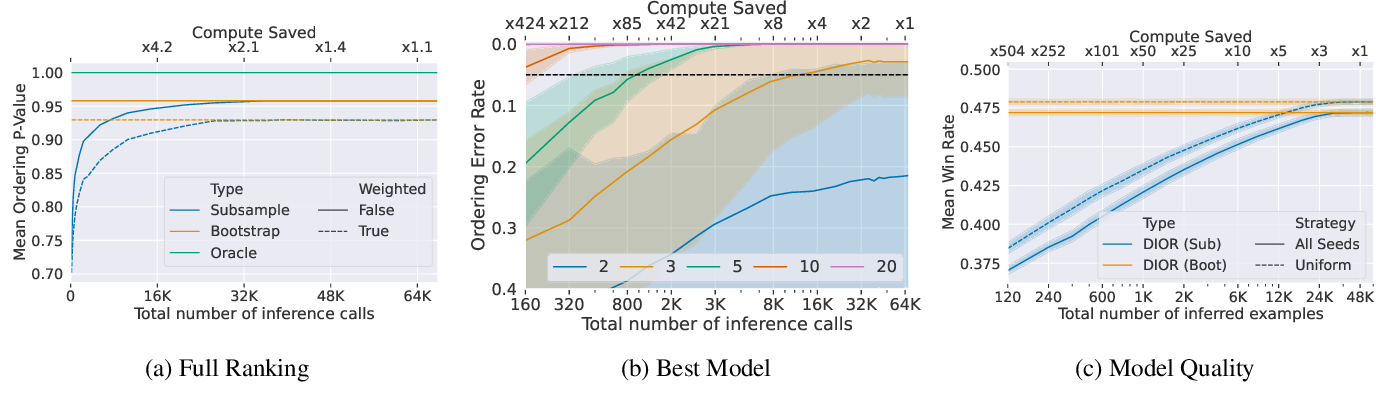













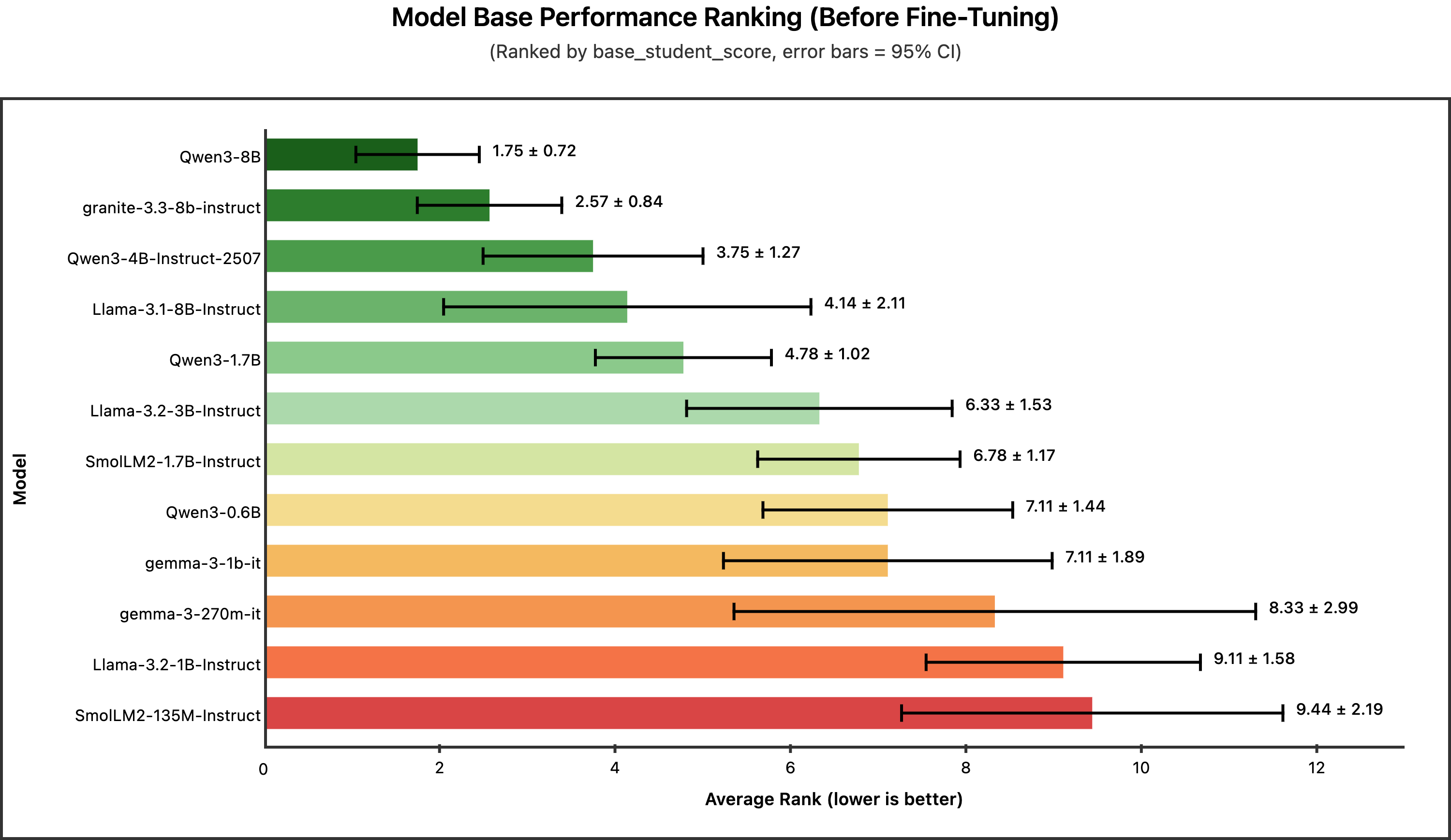



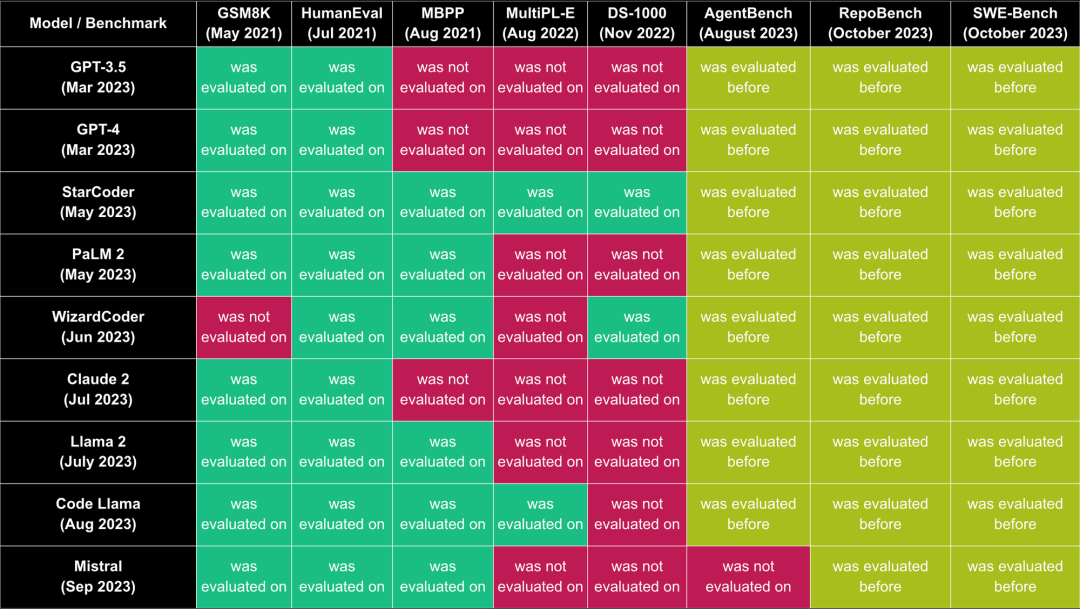


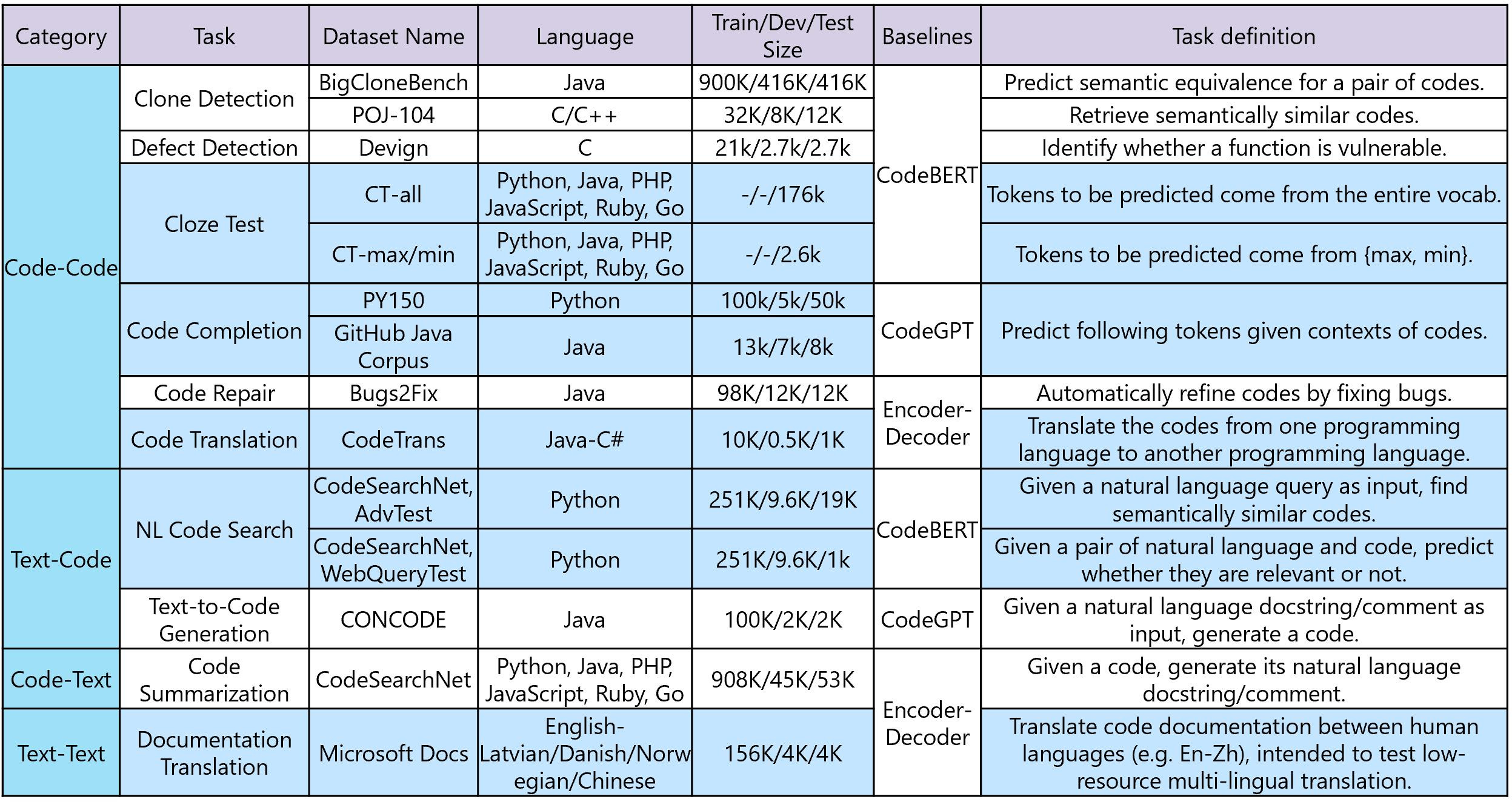
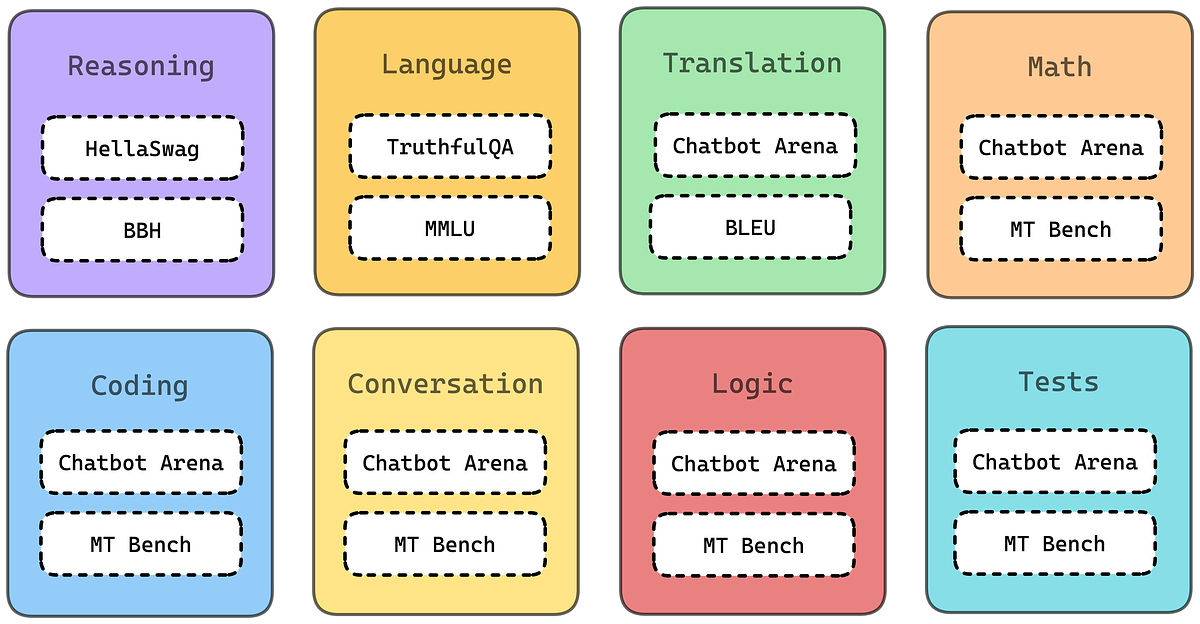



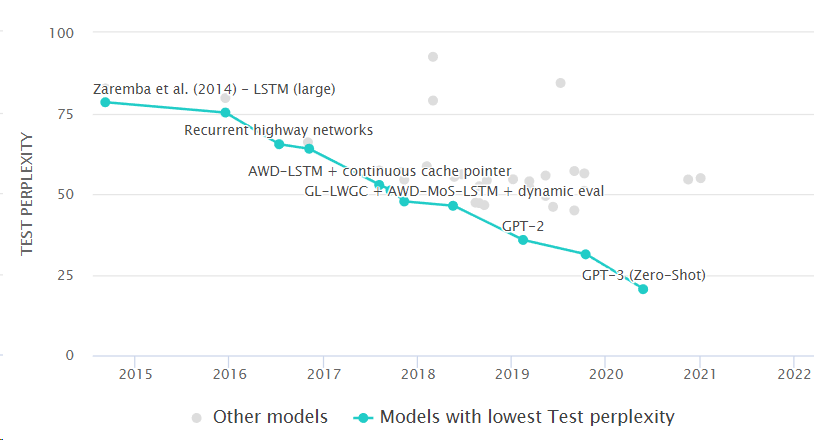

.png)